개요
Node Selector와 Node Affinity 기능에 대하여 알아보겠습니다.
용도
두 기능의 용도는 Pod를 내가 원하는 Node에 배치하고 싶을 때 사용합니다.
Node Selector
동작 방식
특정 node에 Label을 설정 한 다음 node와 동일한 Label을 소유한 Pod만 특정 Node에 배치하는 것입니다.
다음 그림은 Node1에 size: Large라는 Label를 설정 후 size: Large를 가진 Pod만 Node1에 배포하는 그림입니다.

Node에 Label 확인
#kubectl get nodes --show-labels
#kubectl get node worker1 --show-labelsNode에 Label 설정
kubectl label node <nodename> <label-name>=<label-value>
#kubectl label node worker1 size=Large
Node에 Label 제거
설정할 때 사용한 명령에서 <label-name>=<label-value> 를 <label-name>- 으로 변경하면 됩니다.
kubectl label node <node-name> <label-name>-
Pod에 NodeSelector 설정
pod를 어느 node에 배포 할 지를 설정 합니니다.
nodeSelector를 추가하면 됩니다.
nodeSelector:
key: Value
apiVersion: v1
kind: Pod
metadata:
labels:
run: node-selector
name: node-selector
spec:
containers:
- image: nginx
name: node-selector
nodeSelector:
size: LargeNodeSelector의 한계
"or 조건" 또는 "Not 조건" 으로 Label을 설정할 수가 없습니다.

예를 들어 Node가 아래 왕같이 size: medium을 가진 node4가 추가되어 Pod들 중 size: large를 가진 Pod에 size: mdium을 추가하여 node1 또는 node4에 배포하고 싶지만 Node Selector는 1개의 Label만을 지원하기 때문에 이를 할 수가 없습니다.

Pod의 Node Selector에 2개의 Label을 넣으면 Pod가 생성은 되나 scheduling 되지 았습니다.


Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 52s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint
{node-role.kubernetes.io/control-plane: }, 3 node(s) didn't match Pod's node affinity/selector.
preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling.
이렇기 때문에 이를 해결하기 위해서 나온 것이 Node Affinity입니다.
Node Affinity(Node 선호도)
https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#node-affinity
개념
Node affinity는 NodeSelector와 개념적으로 유사하나, Node labels을 사용하여 여러 조건을 설정하여 Node에 설정한 조건에 맞는 Pod만을 배포 하고 싶을때 사용합니다.
단순히 node label과 pod label일 같냐 아니냐로 동작하는 것은 아닙니다.
nodeAffinity types
node의 label이 변화하면 Pod를 어떻게 처리할지를 결정합니다.
2개의 type이 존재하며 type을 분석하면 아래와 같습니다.
type1 : requiredDuringSchedulingIgnoredDuringExecution
- 규칙과 일치하지 않으면 pod를 scheduling 하지 않습니다.
- 이미 실해 중인 pod에 대해서는 규칙을 적용하지 않습니다.
- nodeselect와 기능을 동일 하지만 좀 더 복잡하게 사용가능 합니다.
type2 : preferredDuringSchedulingIgnoredDuringExecution
- scheduler는 규칙을 충족하는 노드를 찾으려고 시도합니다.
- 일치하는 노드를 사용할 수 없는 경우 schedule는 원래 방식대로 동작하여 node에 Pod를 배치합니다
- weight를 사용하여 pod 배치 우선순위를 결정합니다.
type 분석
nodeAffinity 에서는 Pod에 대하여 node label maching 검사 시기를 를 2가지로 분류하고 있습니다.
DuringScheduling : 스케쥴링 하려는 Pod를 검사
DuringExecution : 이미 스케쥴링 된 Pod를 검사
그리고 Pod의 node label matching 통과 조건을 3가지로 분류 하고 있습니다.
required : 전부 일치
prefered : node label과 일치하는게 있으면 해당 node를 선택하지만 없으면 기존 scheduling 방식으로 node선택
ignored : node label matching을 무시
2개 type의 nodeAffinity
requiredDuringSchedulingIgnoredDuringExecution
preferredDuringSchedulingIgnoredDuringExecution
| node Appty type | DuringScheduling (Pod의 sheduling시 영향줌) | DuringExcution (실행중인 pod에 영향줌) |
| type 1 | required (규칙과 일치 시) | Ignored (규칙을 무시) |
| type 2 | preferred (규칙을 선호) | Ignored (규칙을 무시) |
| type 3 (not supported) | required (규칙과 일치 시) | required (규칙과 일치 시) |
적용 우선 수위는 requiredDuringSchedulingIgnoredDuringExecution가 더 높습니다.
Pod에 추가 방법
node affinity type : requiredDuringSchedulingIgnoredDuringExecution
규칙과 일치시
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: NotIn
values:
- Largenode affinity type :preferredDuringSchedulingIgnoredDuringExecution
규칙과 일치 및 선호도(weight) 반영
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: size
operator: In
values:
- large
- weight: 50
preference:
matchExpressions:
- key: size
operator: In
values:
- mediumnodeAffinity type 세부 항복
nodeSelectorTerms (requiredDuringScheduling 전용)
matchExpressions를 array로 가집니다.
weight (preferredDuringScheduling 전용)
어떤 matchExpressions을 먼저 적용하지 우선 순위를 선택 합니다.
matchExpressions (공통)
node selector와 동일한 역할을 합니다. 다만 operator가 추가되었습니다.
| operator | 설명 |
| In | values 에 나열된 값들중 하나를 가진 Node에 Pod를 배치하게 합니다. |
| NotIn | values에 나열이 안된 Node에 Pod를 배치하게 합니다. |
| Exists | key 값을 가진 Node에 Pod를 배치하게 합니다. |
| DoesNotExit | key 값이 없는 Node에 Pod를 배치하게 합니다. node taints로 대체 가능 |
weight
weight가 높은 곳에 pod를 먼저 배치합니다.
weight는 1부터 100까지의 정수 값을 가질 수 있습니다. 그리고 높은 weight 값이 선호도가 높습니다.
최종 yaml 파일
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: node-affinity
name: node-affinity
spec:
replicas: 2
selector:
matchLabels:
app: node-affinity
strategy: {}
template:
metadata:
labels:
app: node-affinity
spec:
containers:
- image: nginx
name: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: In
values:
- large
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: size
operator: In
values:
- large
- weight: 50
preference:
matchExpressions:
- key: size
operator: In
values:
- mediumnodeAffinity 우선 순위
1 순위 : requiredDuringSchedulingIgnoredDuringExecution
2 순위 : preferredDuringSchedulingIgnoredDuringExecution
동작 방식
- 스케줄러는 먼저 requiredDuringSchedulingIgnoredDuringExecution 조건을 만족하는 모든 노드를 찾습니다. 이 단계에서 조건을 만족하지 못하는 노드는 후보군에서 제외됩니다.
- 그 다음, preferredDuringSchedulingIgnoredDuringExecution 조건에 따라 점수를 매겨 후보 노드들을 평가합니다. 이 점수는 노드가 파드에 얼마나 적합한지를 나타냅니다.
- 최종적으로, 가장 높은 점수를 받은 노드(들) 중에서 하나를 선택하여 파드를 배치합니다.
taints and Tolerations vs Node Affinity
taints and Tolerations (node가 scheduilng 제어)
node가 scheduling 된 Pod를 받을지 말지를 결정합니다.
단점 : taint가 없는 node는 Pod의 toleration 보지 않기 때문에 toleration이 있는 Pod도 scheduilng 될 수도 있습니다.
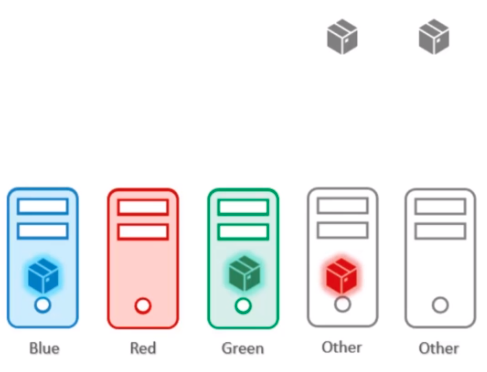
Node Affinity (Pod가 scheduilng 제어)
Pod가 해당 Node에 scheduilng 될 수 있는 지를 결정 합니다.
단점 : Node Affinity 설정이 없는 pod는 label이 있는 node에 scheduilng 될 수도 있습니다. 왜냐하면 기본 scheduler는 node의 label을 보지 않고 scheduling 하기 때문입니다.
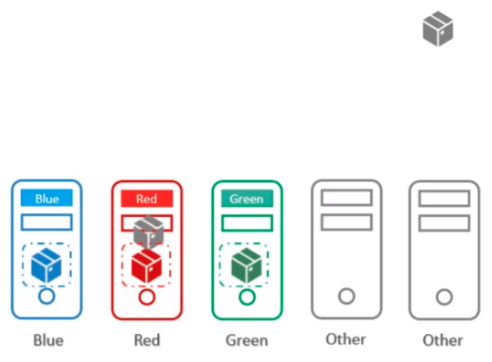
결론
pod를 원하는 node에 정확히 scheduilng 하려면 taint, toleration, node affinity를 모두 사용해야 합니다.
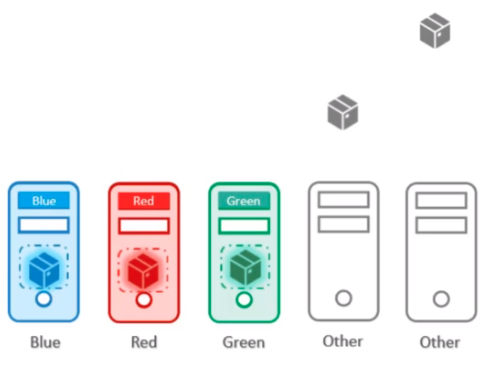
정리
node selector
특정 node에 Label을 설정 한 다음 node와 동일한 Label을 소유한 Pod만 특정 Node에 배치하는 것입니다.
node selector를 사용해서 간단하게 pod를 원하는 node를 배치할 수 있지만 복잡한 조건을 주어서 pod를 node에 배치하려면 node affinity를 사용해야 합니다.
node affinity
node selector의 확장판, lablel을 2개이상 사용하거 조건을 만들고 싶을떄 사용합니다.
node affinity는 2개의 type이 지원합니다.
type1 : requiredDuringSchedulingIgnoredDuringExecution
- 규칙과 일치하지 않으면 pod를 scheduling 하지 않습니다.
- 이미 실해 중인 pod에 대해서는 규칙을 적용하지 않습니다.
- nodeselect와 기능을 동일 하지만 좀 더 복잡하게 사용가능 합니다.
type2 : preferredDuringSchedulingIgnoredDuringExecution
- scheduler는 규칙을 충족하는 노드를 찾으려고 시도합니다.
- 일치하는 노드를 사용할 수 없는 경우 schedule는 원래 방식대로 동작하여 node에 Pod를 배치합니다
- weight를 사용하여 pod 배치 우선순위를 결정합니다.
Next Post
'Cloud > k8s-CKA' 카테고리의 다른 글
| [CKA] 10. Namespace resource 제어 방법 (0) | 2023.03.04 |
|---|---|
| [CKA] 9. Pod resource 제어 방법 (0) | 2023.02.14 |
| [CKA] 7. schedule (nodeName, taint, toleration) (0) | 2023.02.02 |
| [CKA] 6. Object를 관리하는 방법 3가지 (0) | 2023.01.29 |
| [CKA] 5. namespace (0) | 2023.01.24 |